
Понятие "архитектура ЭВМ" является весьма распространенным и может быть рассмотрено с различных точек зрения. Как и для всякого широкого понятия, здесь существует несколько подходов. С технической точки зрения термин архитектура часто подразумевает функциональные возможности системы, реализуемые через набор команд ЭВМ (рассмотрение с точки зрения набора команд). Почти также часто под понятием архитектура понимаются физические компоненты вычислительной системы и их логические, физические и функциональные связи (рассмотрение с точки зрения технологии и организации). Опытный системный программист может получить полное представление о некой системе, собрав о ней соответствующие данные на основе одной или обеих из указанных концепций.
Предлагаемый нами подход может показаться специалисту весьма неортодоксальным, однако он позволяет открыть новые возможности оценки как перед новичком, так и перед специалистом. Одно из его отличий состоит в первую очередь в попытке проследить архитектурные развития большинства доступных коммерческих систем. Предполагается, что такой подход позволит с большей легкостью оценить преимущества системы iAPX 432.
Большинство доступных коммерческих систем были результатом многолетнего последовательного циклического поступательного процесса. Для пользователей это представлялось в виде серий более совершенных, более обобщенных, более быстрых и более экономически эффективных моделей.
Требования к этим системам также изменялись, но в целом можно сформулировать обобщенную шкалу требований, отражающую историческое развитие коммерческих вычислительных систем:
Можно сказать, что наиболее успешными коммерческими системами оказались те, которые, изначально удовлетворяя первым требованиям, смогли в своем развитии удовлетворить и последующим более "продвинутым" вышеописанным требованиям. Зачастую такой успех достигался в одном семействе вычислительных машин. Однако порой семейство должно было прекратить свое существование, уступив дорогу новому, а в ряде случаев все предприятие по производству вычислительных машин закрывалось или продавалось.
В любом случае эволюция развития вычислительной техники свелась к последнему из приведенных нами требований, т. е. к наличию многопроцессорной системы, большей частью с общей памятью, разделяемой каждым процессором. Для большинства коммерческих систем это требование было удовлетворено за несколько этапов развития.
Вне зависимости от области технологии производства вычислительной техники, в которой происходит эволюция, можно с уверенностью сказать, что резко снизившаяся стоимость производства в сочетании с требованием увеличения вычислительной мощности и разнообразия применений привела разработчиков архитектуры вычислительных систем общего назначения к решениям, предполагающим использование структур с мультиобработкой. В специфике этих решений можно усмотреть много различий. В целом, однако, доминирует один ведущий принцип, который предполагает наличие набора доступных процессоров, обслуживающих сеть взаимосвязанных программных единиц. Иногда эти сети организованы в виде древовидных структур или связанных древовидных структур, но в любом случае коммуникации между асинхронными программными единицами обеспечиваются одним или несколькими механизмами синхронизации.
В наиболее упрощенной (и абстрактной форме) эту модель с мультиобработкой можно представить себе в виде схемы, показанной на
Некоторое представление готовой к выполнению задачи, как, например, сообщение, указывающее на "блок управления задачей" (при использовании старой терминологии, или на объект "процесс" - термин, который мы будем использовать позднее), помещается в очередь готовности в направлении, указанном стрелкой. Затем программа закрепляется за доступным процессором, также представленным указателем в соответствующем блоке управления (объект "процессор"), при достижении им конца своей очереди. Эта пара очередей может быть названа диспетчерским портом.
Обработка программы (процессором, за которым она закреплена) продолжается до тех пор, пока это не станет невозможным по какой-либо причине. (Программа закончила свое выполнение, процесс "супервизор" выдал команду на ее удаление, задача перешла в состояние ожидания или же завершился отведенный ей квант времени.) В этот момент программа либо открепляется, либо помещается в соответствующую очередь ожидания (не показанную на рисунке). Процессор в свою очередь снова помещается в очередь доступных процессоров в ожидании новой задачи. В тот момент, когда заблокированная программная единица снова становится готовой к выполнению, она удаляется из очереди ожидания и вновь помещается в очередь готовности.
Модель с параллельной обработкой имеет ряд привлекательных черт, одной из которых является ее существенная независимость от любой базовой семантической модели структуры и от выполнения самой программы. Важно отметить, что эта модель в равной степени может быть использована для мультипрограммирования на Фортране, для программ на Коболе и языке Ада, включая те языки, которые имеют мультизадачные структуры подобно тому, как это реализовано в программах на языке ЛИСП, подобному ему языке, или же на их сочетаниях. Кроме этого, поведение подобной модели не зависит, за исключением производительности, от количества (одного или нескольких) используемых процессоров.
Разработка системы по вышеописанному принципу создает ряд вопросов. Должна ли система иметь одну разделяемую (центральную) память, или же отдельную память для каждого процессора, или комбинации общих и разделяемых областей памяти? Для обеспечения удовлетворительных характеристик в каждом из этих вариантов доступ к памяти каждого из процессоров должен поддерживаться в достаточно широком диапазоне (а в случае использования разделяемых областей, также должна обеспечиваться достаточная скорость коммутации и надежность [60]). Такие структуры должны гарантировать близкую к линейной зависимость производительности от числа добавляемых процессоров по крайней мере для некоторого приемлемого числа процессоров. Не менее важным является определение путей доступа к устройствам внешней памяти и другим устройствам ввода-вывода.
Представляет интерес использование отдельной памяти для каждого из процессоров, поскольку это позволяет повысить устойчивость к отказам, а также повысить производительность в системах специального назначения. Назовем такую организацию многомашинным решением. (Хорошим примером могут служить системы Tandem [5].) К сожалению, в тех случаях, когда речь идет о системах общего назначения, многомашинные системы имеют два существенных недостатка. Во-первых, в распределенной памяти трудно, если не невозможно, моделировать и реализовывать семантику разделяемых переменных. К сожалению, такие семантики являются интегральной частью почти всех широко используемых языков высокого уровня. Многомашинный подход, следовательно, несовместим с задачами системы общего назначения, которая используется весьма широким классом программистов. Во-вторых, коды программных единиц, обрабатываемые более чем одним процессором, должны копироваться в приватную область памяти каждого из этих процессоров и только потом обрабатываться ими. Такое усложнение представляется приемлемым с точки зрения повышения отказоустойчивости, особенно в тех случаях, когда объем копируемых кодов может быть сведен к конкретным резидентным системным модулям. Однако в тех случаях, когда основным требованием является поддержание баланса динамической загрузки процессоров по некоторому общесистемному критерию, частое дополнительное копирование становится обременительным. Далее, приватная память каждого из процессоров в N-процессорной системе необходимо ограничена 1/N частью общего объема памяти. Следовательно, в системах с распределенной памятью вероятность возникновения "пробуксовки" несоизмеримо больше при использовании отдельной памяти для каждого из процессоров, чем при использовании в N раз большей разделяемой памяти.
Одна общая разделяемая память является в большинстве случаев наиболее приемлемым решением, несмотря на то, что при любом используемом механизме коммутации, используемом для распределения информационного потока между процессорами и разделяемой ими памятью, существует верхняя практическая граница числа используемых процессоров, в пределах которой загруженность коммутационных каналов не оказывает существенного влияния на общую производительность системы. (Этот предел может быть определен эмпирически.) Назовем такое решение многопроцессорной системой. Основным примером этой системы является система i432.
Многопроцессорные системы могут сильно отличаться друг от друга в исполнении и в способах обработки отдельных программных единиц. Но даже с учетом этого архитектуры больших систем общего назначения сходны друг с другом. На верхнем уровне абстракции они выступают в качестве суперструктур многопроцессных систем. К сожалению, поскольку большинство таких систем развиваются "снизу вверх", их реализация и режимы их использования для большого числа пользователей в ряде важных случаев остаются различными.
Перед проектировщиками, которые начинают разработку "с нуля" при подходе "сверху вниз" и которые в состоянии наиболее полно учесть все ошибки и хорошие идеи других, открывается возможность создания наиболее удачных разработок. Они могут начать с элегантности и простоты вышеописанной системы (рис. 1.1) и распространить ее на последующие подуровни. Таким принципом и руководствовалась фирма "Интел" при разработке архитектуры системы i432.
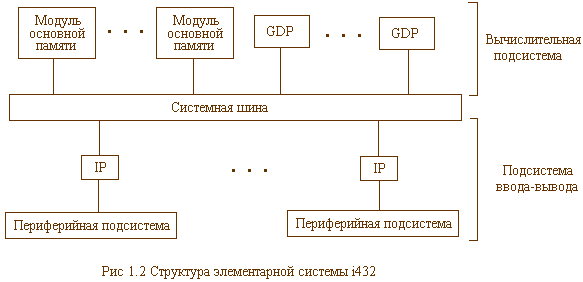
Общая структура архитектуры системы, отражающая взаимосвязь между подсистемой обработки и подсистемой ввода-вывода, приведена на
Фактическая топология системы i432 может отличаться от формы, показанной на рисунке, в зависимости от того, какая конкретная шина и какие внутренние связи используются, а также в зависимости от требований к производительности. (Для системы, содержащей относительно большое число процессоров, скажем более шести GDP и IP, может потребоваться тщательно разработанная сложная структура внутренних взаимосвязей в шине, однако этот аспект здесь мы не рассматриваем.)
Тщательное изучение принципа многопроцессности при определении организации и архитектуры системы позволило реализовать в i432 принцип "прозрачной многопроцессной обработки". Эта простая, но важная концепция означает, что число процессоров в системе i432 может быть увеличено или уменьшено без модификаций в программном обеспечении. Можно даже остановить или запустить процессор в любой момент времени без информирования об этом или разрушения какой-либо части программы. Что более важно, для увеличения числа процессоров не требуется перепрограммирования ни операционной системы, ни прикладной программы.
Интересно отметить, что реализация многопроцессорного принципа в системе i432 не была непосредственно обусловлена традиционным желанием распределения рабочих программ между набором процессоров. Решение внедрить многопроцессорный принцип было обусловлено не только "техническими" причинами. Во-первых, учитывалось то, что к моменту объявления о создании системы i432 будут доступны другие конкурентоспособные архитектуры, различные по стоимости и уровням исполнения. Во-вторых, в отличие от традиционных разработчиков ЭВМ фирмы по производству полупроводников не в состоянии внедрить новый уровень архитектуры за период, меньший чем три или четыре года. (Это обусловливается не только сравнительно небольшими размерами фирм по производству полупроводников, но также и тем фактом, что в текущий момент времени они располагают только одной технологией, позволяющей с разумными затратами реализовать новую архитектуру.)
Эти два фактора заставили проектировщиков фирмы "Интел" искать новый подход, который позволил бы реализовать систему i432 в одной разработке. Принцип многопроцессности является привлекательным для разработчиков еще и с экономической точки зрения, поскольку повышение производительности обеспечивается дублированием процессорной схемы, а не полностью новой проектировкой. Далее, многопроцессорный принцип также обеспечивает концепцию модульного, "полевого" расширения либо системы ввода-вывода, либо обработки данных простой установкой печатной платы. Последняя возможность предоставляет пользователям системы i432 недорогой способ расширения имеющейся у них системы в процессе эксплуатации.

|

|

|