Реализация высокоэффективных межпотоковых взаимодействий в современных многоядерных/многопроцессорных системах
Ада — язык, в котором механизмы межпотоковых (в терминологии Ады — межзадачных) взаимодействий входят в стандарт языка с самой первой его редакции. По мере развития языка развивались и средства межзадачных взаимодействий. Изначально основным механизмом были рандеву между задачами. В стандарте Ада 95, были добавлены защищенные объекты. В Ада 2005 появились synchronized интерфейсы.
Эти механизмы надежны, стандартны и хорошо отлажены. Однако, в некоторых случаях, могут оказаться медленными в силу своей сложности и особенностей реализации.
С недавних пор развитие многоядерных процессоров вышло на новый уровень. Теперь трудно встретить ПК с одним ядром, даже мобильные телефоны оснащаются двуядерным процессорами. Без внимания разработчиков не остается и поддержка межпотоковых взаимодействий. Практически каждый современный процессор поддерживает те или иные команды, специально предназначенные для написания многозадачного кода.
Как воспользоваться эффективными средствами межпотоковых взаимодействий мы и рассмотрим в этой статье.
Организация данных внутри задач
Прежде чем перейти непосредственно к межзадачному взаимодействию, рассмотрим сначала, как организовать данные специфичные для отдельных задач так, чтобы только задача владелец имела к ним доступ.
В программах без многозадачности данные по времени жизни можно разделить на два вида глобальный и локальные. В Аде первые представлены переменными в пакетах на уровня библиотеки:
package body Global_Data is Total_Counter : Natural := 0; end Global_Data;
Локальные данные объявляются в теле процедуры и функции:
procedure Swap (Left, Right : in out Integer) is Temporary : Integer := Left; begin ... end Swap;
При введении многозадачности возникает еще один период — период жизни задачи. Данные, локальные для одно задачи выгодны тем, что их не нужно «защищать» от модификации со стороны конкурирующих задач, как глобальные. В тоже время период их жизни более продолжителен чем у локальных данных.
Локальные для задачи данные могут быть объявлены в теле задачи:
task body Calculate is Result : Calculation_Result; begin ... end Calculate;
Однако не всегда использования данных объявленных таким способом удобно. Некоторым пакетам могут потребоваться свои данные отдельные для каждой задачи. Предлагать пользователям пакета хранить эти данные вне пакета может оказаться неправильно с точки зрения абстракции и инкапсуляции данных. Примерами таких данных могут быть
- всевозможные кеши часто используемых значений
- сессии к БД, внешним сервисам
- открытые файлы данных, протоколов
- и многое другое
В этом случае был бы удобен механизм описания данных по типу глобальных, где данные спрятаны внутри тела пакета, с той лишь разницей, что у каждой задачи будет отдельная копия этих данных. Как раз это и обеспечивает инструкция компилятору (специфичная для компилятора GNAT):
pragma Thread_Local_Storage (LOCAL_NAME);
Эта инструкция позволяет указать, что переменную следует хранить специальным образом, чтобы у каждого потока был свой экземпляр. Реализация этого способа хранения ложиться на ОС и библиотеку окружения. В настоящее время это поддерживается в Solaris, GNU/Linux и VxWorks 6.
package body Task_Data is Total_Counter : Natural := 0; pragma Thread_Local_Storage (Total_Counter); end Task_Data;
Сходного результата можно добиться и Без использования этой директивы, воспользовавшись стандартным настраиваемым пакетом Ada.Task_Attributes. Но к сожалению механизмы реализации этого пакета значительно тяжелее и медленнее, чем Thread_Local_Storage.
Атомарные операции
К простейшим вариантам взаимодействия задач можно отнести ведение общего счетчика. Такие счетчики часто встречаются во всевозможных «умных указателях», контролируемых типах, автоматически уничтожающих объекты, когда счетчик внешних ссылок на объект снижается до нуля.
Если эти типы используются в многозадачном окружении, то счетчик должен быть защищен от одновременной модификации несколькими задачами.
Использования защищенного типа для этих целей может повлечь существенное замедление операций изменения счетчика, в силу того, что сложность вызова защищенной процедуры намного превосходит сложность самой операции наращивания счетчика.
Современные процессоры предоставляют атомарные операции над словами, среди которых есть подходящие для наших целей операции увеличения/уменьшения слова.
Чтобы ими воспользоваться, нам даже не нужно использовать ассемблер, т.к. компилятор GCC GNAT предоставляет встроенные операции, общие для всех поддерживаемых платформ.
Перечень встроенных операций доступен в документации GCC («Built-in functions for atomic memory access») в виде С функций. Например,
type __sync_sub_and_fetch (type *ptr, type value, ...)
Эта функция уменьшает слово по адресу ptr на значение value и возвращает результат. При этом гарантируется атомарность этой операции.
В качестве аргументов GCC поддерживает указатели и скалярные типы, размер которых 1, 2, 4 или 8 байт.
На языке Ада это можно использовать так: Сначала опишем функцию
используя нужные нам типы, затем импортируем ее используя метод Intrinsic (встроенная функция).
use Interfaces; function Sync_Sub_And_Fetch (Reference : not null access Unsigned_32; Increment : Unsigned_32) return Unsigned_32; pragma Import (Intrinsic, Sync_Sub_And_Fetch, "__sync_sub_and_fetch_4");
Теперь, если мы имеем счетчик
Counter : aliased Unsigned_32 := 1; pragma Atomic (Counter); pragma Volatile (Counter);
Мы может атомарно его уменьшить и сравнить результат с нулем так:
if Sync_Sub_And_Fetch (Counter'Access, 1) = 0 then ...
Заметим, что счетчик должен быть Atomic и Volatile чтобы при обращении к нему компилятор не использовали оптимизаций, таких как кэширование значения в регистре и подстановка выражений.
Таким образом, используя встроенные функции компилятора мы можем реализовать работу с атомарным счетчиком, избежав использования защищенных объектов и сохранив при этом относительную независимость от целевой платформы.
Неблокирующие алгоритмы
Другим применением встроенных операций компилятора является реализация Неблокирующих алгоритмов. Отличие неблокирующих алгоритмов в том, что все конкурирующие потоки пытаются совершать полезную работу, а не просто ожидать освобождения критического ресурса.
Неблокирующие алгоритмы предпочтительны по нескольким причинам
- им не свойственны такие проблемы блокирующих алгоритмов, как взаимная блокировка (deadlocks), инверсия приоритетов, зацикливание
- в то время, как поток удерживает блокировку, он может быть приостановлен ОС, в результате того, что у него истек отведенный ему квант времени. Как результат, ни один поток не в состоянии работать в этой критической секции дальше, пока ОС не возвратит управление вытесненному потоку, удерживающему блокировку.
- зависание на блокировке обычно ведет к переключению контекста процессора, что выполняется в режиме ядра и является довольно дорогостоящей операцией как по тактам процессора, так и по инвалидации всевозможных кэшей, конвейеров, устройств предсказания ветвлений.
Ключевой операцией (при одном из подходов к реализации неблокирующих алгоритмов) является операция CAS (Compare And Swap — сравнить и обменять).
Мы можем задать ее уже известным нам способом:
function Compare_And_Swap_32 (Ptr : access Unsigned_32; Old : Unsigned_32; Set : Unsigned_32) return Boolean; pragma Import (Intrinsic, Compare_And_Swap_32, "__sync_bool_compare_and_swap_4");
Работает она так, если слово по адресу Ptr равно Old, то заменить его на Set и вернуть True, иначе ничего не менять и вернуть False. Эта операция выполняется атомарно.
С помощью этой операции мы можем реализовывать различные неблокирующие алгоритмы и сложные структуры данных, не требующие дополнительной защиты. Для примера рассмотрим операцию «положить в стек».
type Node is record Next : aliased access Node; pragma Atomic (Next); pragma Volatile (Next); Data : Integer; end record; Stack : aliased access Node; pragma Atomic (Stack); pragma Volatile (Stack); procedure Push (X : access Node) is Top : access Node; begin loop Top := Stack; X.Next := Top; exit when Compare_And_Swap_32 (Stack'Access, Top, X); end loop; end Push;
Вот стек и элемент, который мы собираемся добавить:
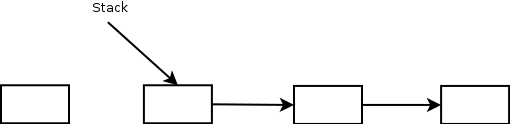
В начале мы читаем верхушку стека — указатель на верхний элемент и помещаем его в поле Next, подвешивая всю цепочку элементов находящихся в стеке на новый элемент.
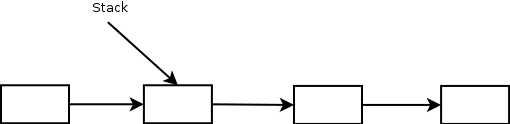
Затем пытаемся заменить верхушку стека за указатель на новый элемент. Эту операцию безопасно выполнить без использования атомарных операций, т.к. другие задачи не увидят новый элемент, пока на него не укажет верхушка стека.
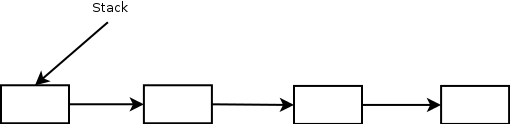
Если никто не поменял стек за время выполнения предыдущих шагов, то операция выполнится успешно и мы выйдем из цикла и процедуры. Если же стек был изменен, то мы повторим все сначала.
Алгоритм операции «положить в стек» очень простой. Он выполняется за один вызов CAS. Нередко, однако, может потребоваться несколько операций изменения данных чтобы перевести структуру их из одного «устойчивого» состояния в другое. В этом случае операция разбивается на несколько атомарных шагов, и конкурирующие задачи могу выполнять эти шаги параллельно. При этом задача, обнаружившая структуру в промежуточном состоянии, переводит ее в устойчивое состояние, прежде чем совершить намеченную операцию, таким образом, «помогая» задаче инициализировавшей первое изменение.
В качестве примера, рассмотрим операцию помещения элемента в очередь.

Она состоит из двух шагов:
- Добавить элемент в цепочку

- передвинуть указатель на конец очереди на новый элемент

Tail : aliased access Node; pragma Atomic (Tail); pragma Volatile (Tail); procedure Append (X : access Node) is Last : access Node; begin loop Last := Tail; if Last.Next = null then -- Добавить элемент в цепочку if Compare_And_Swap_32 (Last.Next'Access, null, X) then -- передвинуть указатель на конец очереди на новый элемент Ignore := Compare_And_Swap_32 (Tail'Access, Last, Last.Next); return; end if; else -- Конец очереди не указывает на последний элемент -- сначала исправим это Ignore := Compare_And_Swap_32 (Tail'Access, Last, Last.Next); end if; -- И повторим все с начала end loop; end Append;
Обратите внимание, что нет никакой гарантии, что операция добавления выполнится за один, два или N шагов. Задача может зациклиться, помогая другим задачам привести очередь в «стабильное» состояние. Однако, есть гарантия, что с каждым циклом продвигается хотя бы один конкурирующий поток, т.к. за каждый цикл добавляется, как минимум один элемент.
Следует также заметить, что в связи с особенностями аппаратной архитектуры многоядерных/многопроцессорных систем, если одна задача начнет «помогать» доделывать ее операцию, то вероятнее всего производительность первой упадет, а не вырастет. Это легко понять, если принять во внимание существование многоуровневых кэшей и общих шин данных. Поэтому таких коллизий нужно, по возможности, избегать.
Несмотря на кажущуюся простоту, неблокирующим алгоритмам свойственны свои проблемы. Одной из таких проблем является «ABA-problem», суть которой в том, что состояние объекта может измениться, а задача этого не заметит, если численное значение, проверяемое в CAS операции останется прежним.
Например, задача 1, выполняя оператор
Ignore := Compare_And_Swap_32 (Tail'Access, Last, Last.Next);
была вытеснена системой, сразу после вычисления Last.Next.
За время, пока задача простаивала, элемент, на который указывает Last был удален из списка и вновь добавлен. Содержимое поля Next изменилось. Но задача 1, получив управление, запускает CAS. Допустим Last = Tail, и операция отрабатывает успешно, заменив содержимое Tail на уже неактуальное значение Last.Next.
Решения этой проблемы могут быть разными. Например hazard pointers — указатели хранящие ссылки на объекты которые сейчас в работе, и которые нельзя удалять. Например, сохранив в таком указателе Last, мы бы предотвратили его повторное попадание в очередь.
Либо встраиванием в указатель поля «версия». Если бы Last содержал такое поле, то CAS не сработал бы, т.к. имел бы более старую версию чем Tail, хотя они оба указывали бы на один объект в памяти.
Смешивание блокирующих и неблокирующих подходов
Допустим мы реализовали некоторую очередь заданий при помощи неблокирующих структур. Если заданий в избытке, задача, их исполняющая, работает эффективно. Но, если заданий не хватает, она будет просто греть воздух в цикле, пытаясь получить несуществующие задания.
Тут как раз пригодиться комбинированный подход. Мы можем использовать оптимизированный семафор. Он организован как пара: атомарный флаг и защищенный объект.
Пока заданий в достатке, семафор открыт, а операция его открытия не доходит до защищенного объекта, благодаря атомарному флагу и выполняется очень быстро. Мы можем выполнять ее при каждом помещении задания в очередь, практически не теряя в производительности.
Когда задания кончаются, исполняющая задача, закрывает семафор, сбрасывая флаг и зависая на входе защищенного объекта. Теперь она не нагружает даром процессор. А после появления первого задания, операция открытия спустит семафор.
protected type Barier_Lock is entry Wait; entry Release; private Locked : Boolean := True; end Barier_Lock; type Barier_Flag is (Open, Closed); for Barier_Flag'Size use 8; pragma Atomic (Barier_Flag); pragma Volatile (Barier_Flag); type Barier is record Flag : aliased Barier_Flag := Open; Lock : Barier_Lock; end record; procedure Release (Self : in out Barier) is begin if Self.Flag = Closed and then CAS (Self.Flag'Access, Closed, Open) then Self.Lock.Release; end if; end Release; procedure Wait (Self : in out Barier) is begin Self.Flag := Closed; Self.Lock.Wait; end Wait;
Заключение
Мы использовали описанные здесь приемы для написания эффективной шины доставки сообщений. В ее составе нам удалось реализовать неблокирующие структуры для очереди сообщений, очереди широковещательных сообщений, планировщика для управления задачами, обработчиками сообщений, и оптимизированный семафор. Тесты показали приемлемую производительность, а код остается довольно читаемым.